Advanced Image Video Recognition
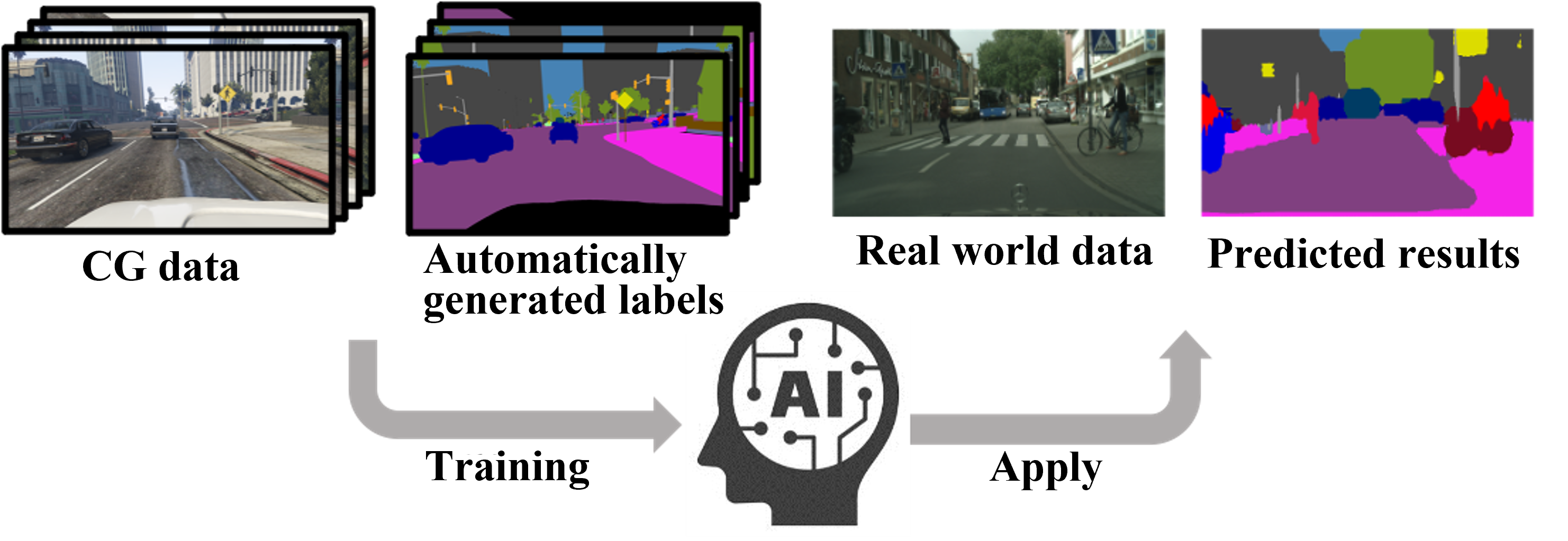
Domain Adaptation Based on Art Style Transformation
Training an artificial intelligence (AI) system requires a significant amount of data and labels for that data. For example, to build an AI system that can distinguish between dogs and cats, we need images and labels that indicate whether an image contains a dog or a cat. On the other hand, preparing such labels for a large amount of data requires a lot of effort, so AI that can learn from a small amount of data is being explored. The Laboratory of Media Dynamics has developed an AI system that can apply knowledge extracted from easily labelable data to unlabeled data. Specifically, by using knowledge extracted from CG data such as games when learning real-world data, we have developed an AI technology that does not require labeling of real-world data.
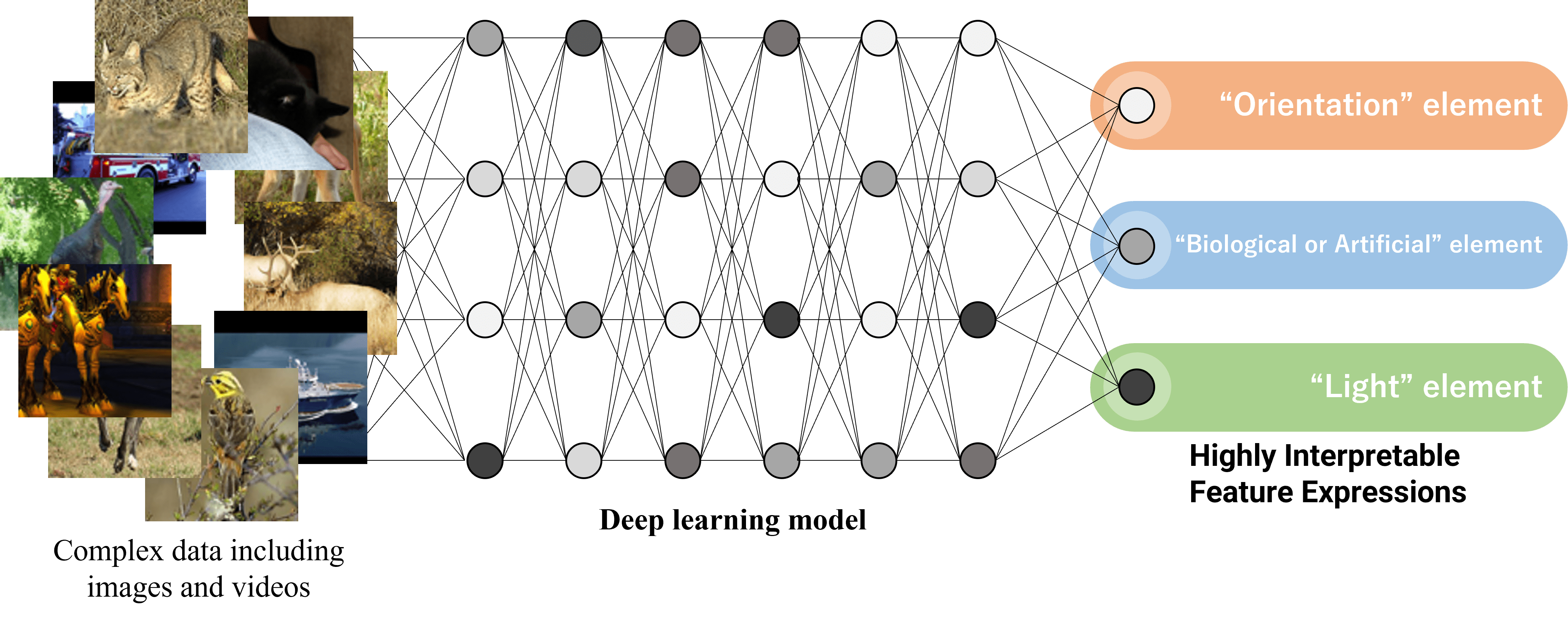
Representation Learning for Acquisition of Highly Interpretable Feature Expressions
In recent years, deep learning (DL) has been piquing research interest for its ability to automatically extract features from complex data, including images and videos, and for its ability to achieve high-accuracy in various tasks. On the other hand, features extracted by conventional DL have low interpretability, making it difficult for humans to understand these features. Understanding features of input data that DL focuses on is critical for improving accuracy and reliability and will be a significant opportunity for DL advancement. Therefore, the Laboratory of Media Dynamics is working on obtaining feature representations that can be used in various tasks by separating extracted features by elements such as shape and color. This research is expected to result in the development of DL methods with higher interpretability by analyzing the extracted features.