Vision Language Integration
Image and Video Retrieval from Text Based on Image Generation Methods
With the spread of mobile terminals and social media, the number of images and videos available on the web and personal terminals is increasing exponentially. There is a need to develop image/video retrieval technology that enables individuals to easily and accurately search for desired images and videos. Conventionally, such image/video retrieval technology has been realized by using text as a query and searching for content with similar text labels. On the other hand, it is difficult to present the image or video that a user needs when the relevant text label is not assigned to the search target. Therefore, in the Laboratory of Media Dynamics, we have developed an image/video retrieval method that does not rely on text labels while using text as a query. Specifically, by employing deep image generation technology, which has been piquing interest in recent years, we have developed a technology that can search for images and videos based on their features after generating images from the text of the query and thus can retrieve images and videos desired by a user.
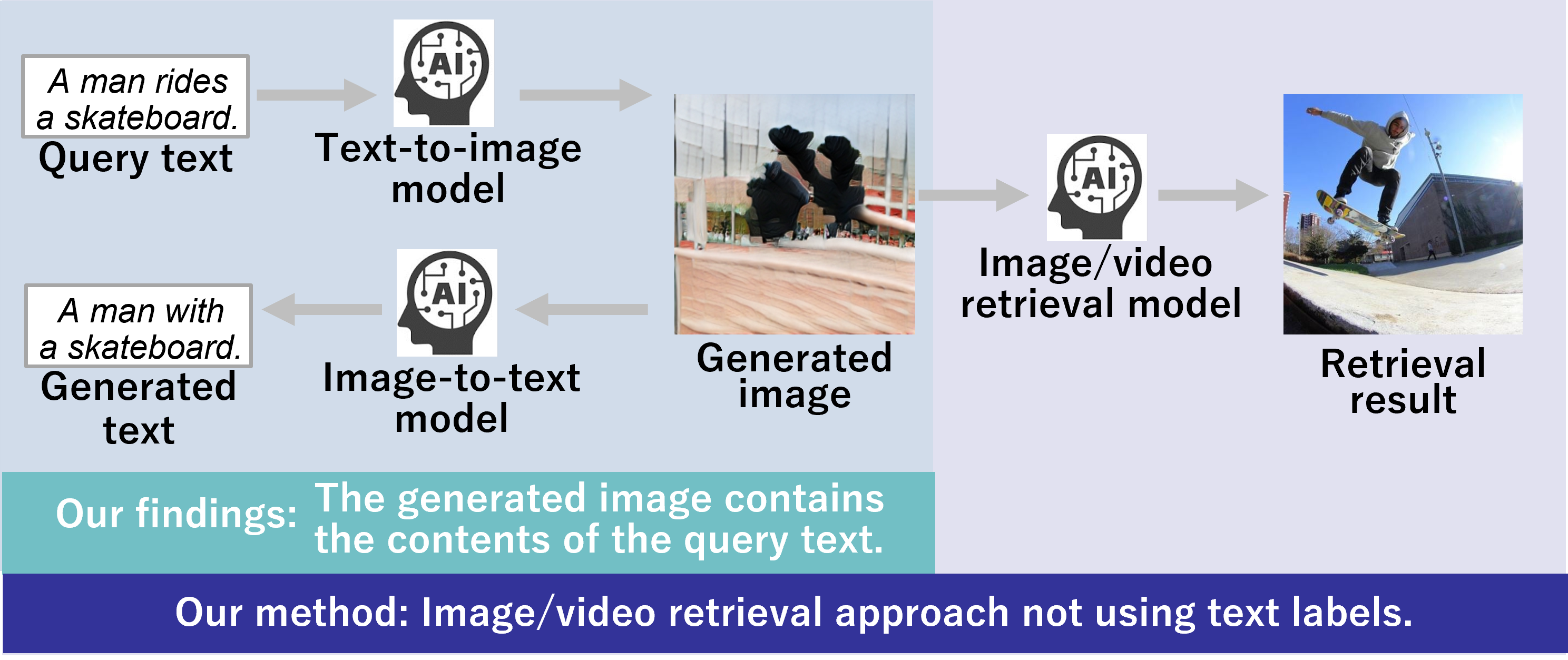
Image and Video Retrieval Based on User Interaction
Previous image/video retrieval methods are built on the premise that a query that accurately describes the image or video to be retrieved is given. Therefore, when the query given by a user is ambiguous, or when multiple similar images or videos are included among the search candidates, it is difficult to obtain highly accurate search results in a single search. Thus, in the Laboratory of Media Dynamics, we have developed an image/video retrieval method that can improve the retrieval accuracy based on user interaction. Specifically, the retrieval system analyzes a query and search candidates given by the user, devises questions that can narrow down the candidate images, and presents them to users. By simply answering the questions presented by the retrieval system, a user can narrow down the desired images and videos as if interacting with AI.
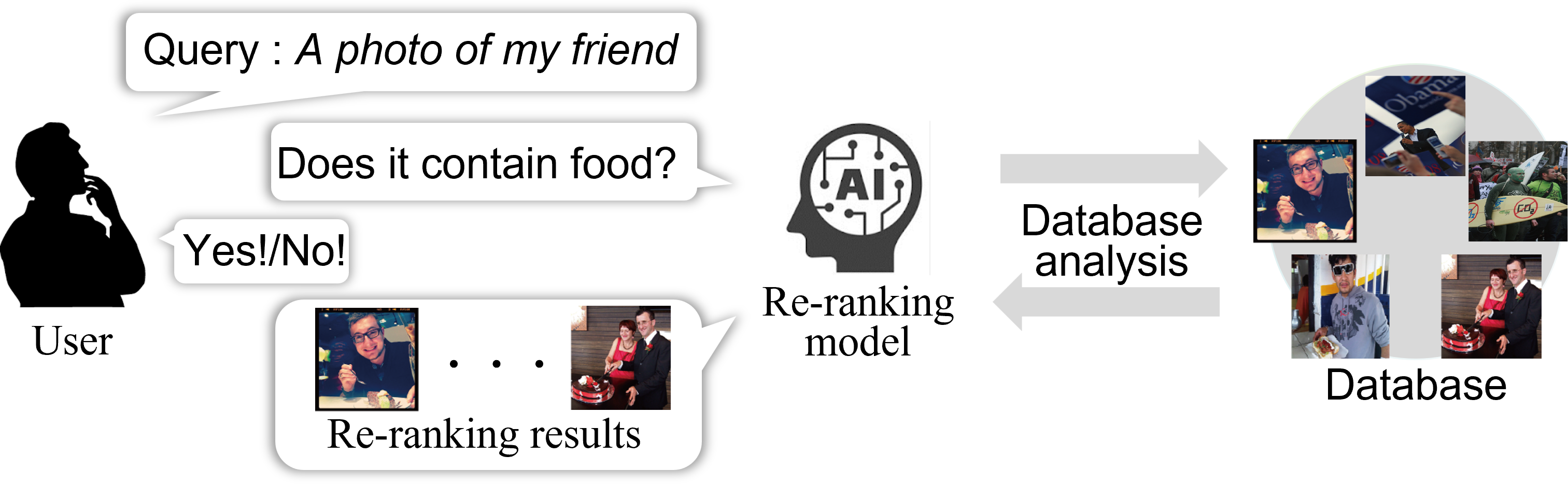
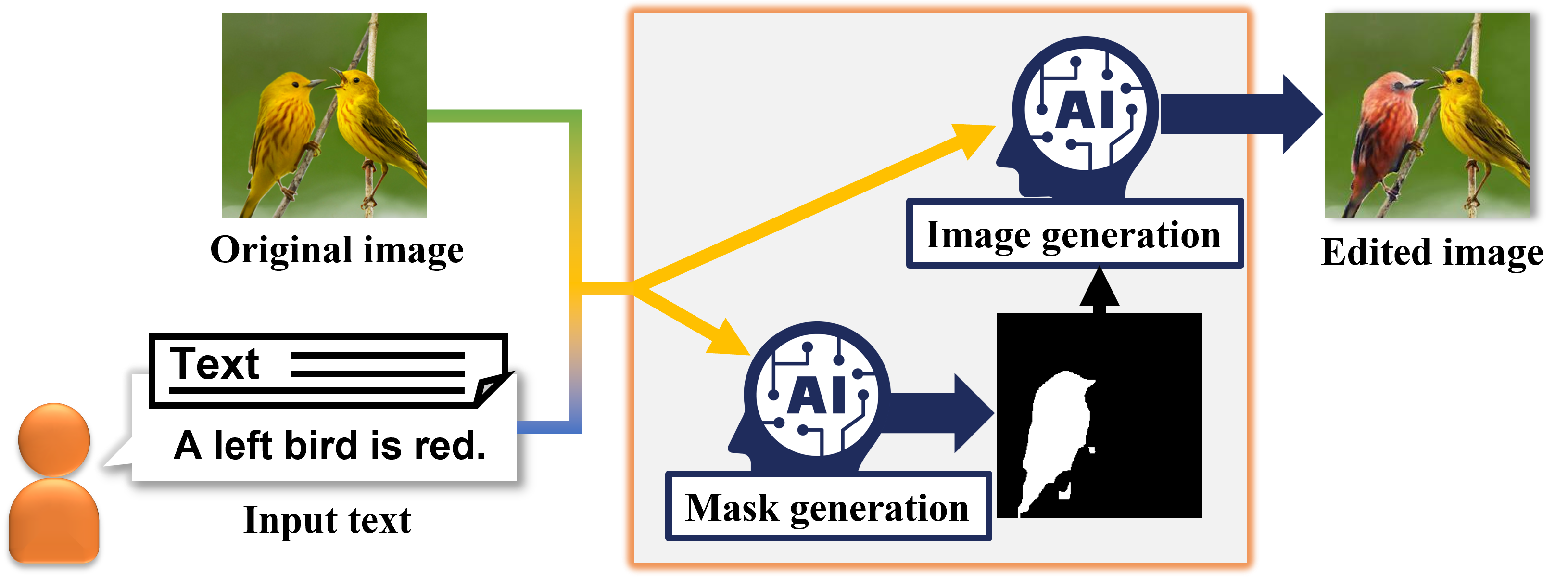
Image Editing Based on Text
In recent years, with the prevalence of mobile devices, it has become easier to share pictures with others through social networking services such as Facebook and Instagram. In this situation, there is a growing demand for image editing technologies to improve image appearances, and by using applications that incorporate these technologies, users can edit images according to their intentions. On the other hand, existing applications require complicated operations to perform advanced editing, so there is a need to develop a technology that enables automatic image editing according to a user’s intention. Therefore, in the Laboratory of Media Dynamics, we are constructing an automatic image editing technique that uses text to indicate a user’s editing intention. Specifically, by using adversarial generative networks and performing cross-modal analysis of visual and verbal information, we are developing a technology that enables users to edit images using only text input and speech.