過去のお知らせ
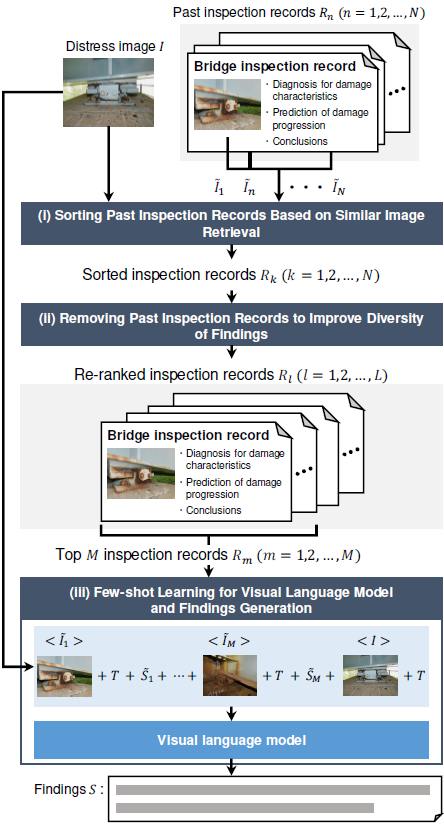
視覚言語モデルのIn-context Few-shot Learningによる構造物劣化画像からの自動所見生成に関する論文が、Journal of Robotics and Mechatronics(Impact Factor: 1.1)に採録されました。
視覚言語モデルのIn-context Few-shot Learningによる構造物劣化画像からの自動所見生成に関する論文が、Journal of Robotics and Mechatronics(Impact Factor: 1.1)に採録されました。
Yuto Watanabe, Naoki Ogawa, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama, “Automatic findings generation for distress images using in-context few-shot learning of visual language model based on image similarity and text diversity,” Journal of Robotics and Mechatronics (Accepted for publication)