視覚・言語融合
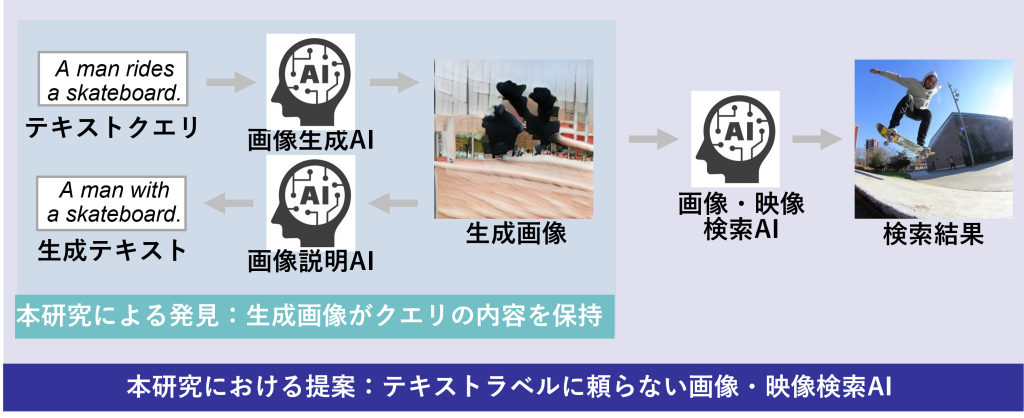
画像生成手法に基づくテキストからの画像・映像検索
携帯端末やソーシャルメディアの普及に伴い,Web上および個人の端末上に存在する画像や映像等のコンテンツ数は爆発的に増加しています.これらの中からユーザが所望するコンテンツを発見することは困難となっており,ユーザを支援する画像・映像検索技術の実現が必要とされています.従来より,このような画像・映像検索技術は,入力したテキストと類似するテキストラベルを有するコンテンツを探索することで実現されてきました.しかしながら,テキストラベルが検索対象のコンテンツに付与されていない場合,ユーザが必要とするコンテンツを提示することは困難でした.そこで,メディアダイナミクス研究室では,テキストを入力として利用しながらも,テキストラベルが付与されていないコンテンツを検索可能な画像・映像検索手法を構築しました.具体的には,近年注目されている深層画像生成技術を活用し,入力テキストから画像を生成し,その画像と類似した画像・映像を探索することで,ユーザの希望する画像・映像を検索することが可能な技術を実現しました.
ユーザとの対話に基づく画像・映像再検索
従来の画像・映像検索では,検索目的の画像や映像を正確に表現したテキストが与えられることを前提としています.そのため,ユーザの与えるテキストが曖昧である場合や検索候補に類似した画像・映像が複数含まれる場合,一度の検索で高精度な検索結果を得ることは困難でした.そこで,メディアダイナミクス研究室では,ユーザとの対話に基づいて検索結果を改善可能な画像・映像再検索手法を構築しました.具体的には,検索システムがユーザにより与えられたテキストや検索候補を解析することで,候補となる画像を効率的に絞り込むことが可能な質問を考案し,ユーザに提示します.ユーザは検索システムから提示された質問に回答するだけで,AIと対話をするように目的の画像・映像を発見することが可能です.

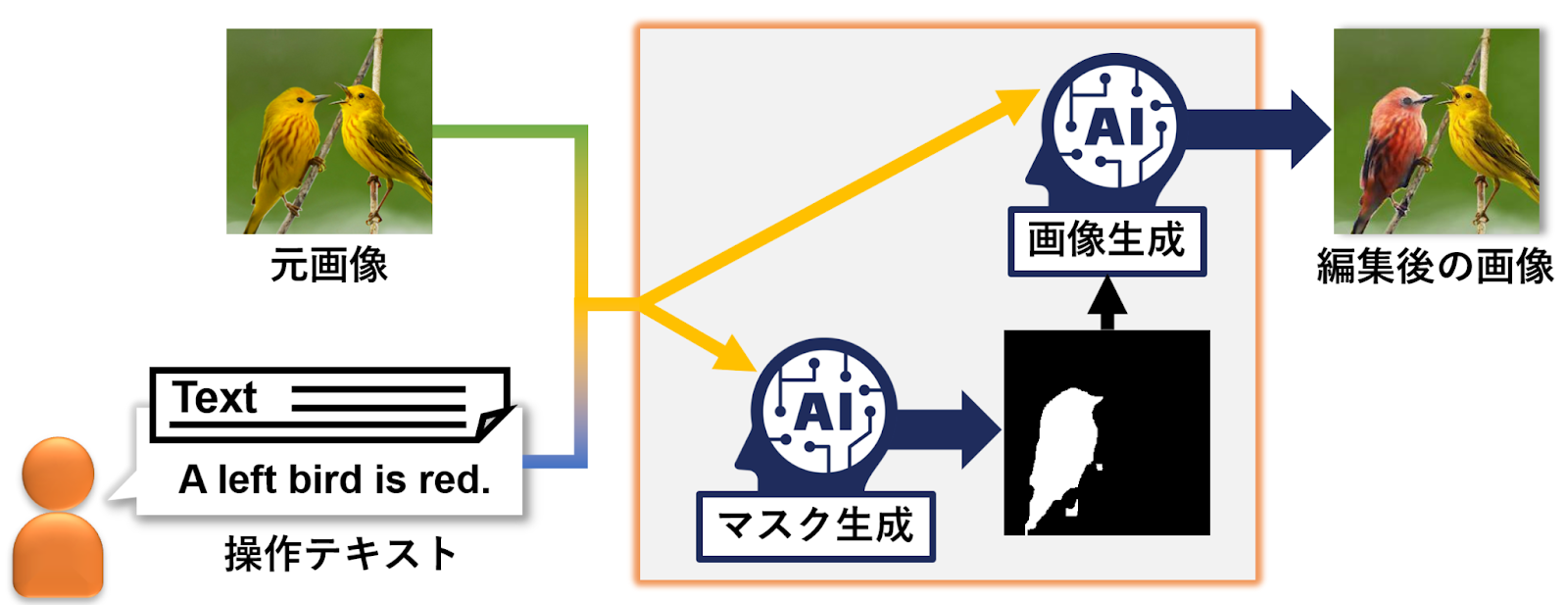
テキストに基づく画像編集
近年,モバイル端末の普及に伴い,気軽に写真を撮影することが可能となっており,FacebookやInstagram等のSNSを通じて第三者へ共有する機会も増加しています.このような状況において,写真をより良く見せるために画像編集技術への需要が高まっており,これらの技術を導入したアプリケーションを利用することでユーザの意図に合わせて画像を編集することが可能です.一方で,既存のアプリケーションでは,高度な編集を行うために複雑な操作が必要であることから,ユーザの意図に沿って自動で画像編集を可能とする技術の構築が必要とされています.そこで,メディアダイナミクス研究室では,ユーザの編集意図を示すテキストを用いた自動画像編集技術を構築しています.具体的には,敵対的生成ネットワークを応用して,視覚と言語情報のクロスモーダル解析を行うことで,ユーザがテキスト入力や発話を行うだけで自動的に画像編集が可能な技術を実現しています.