
高度な画像・映像認識AI
画風変換に基づくドメイン適応
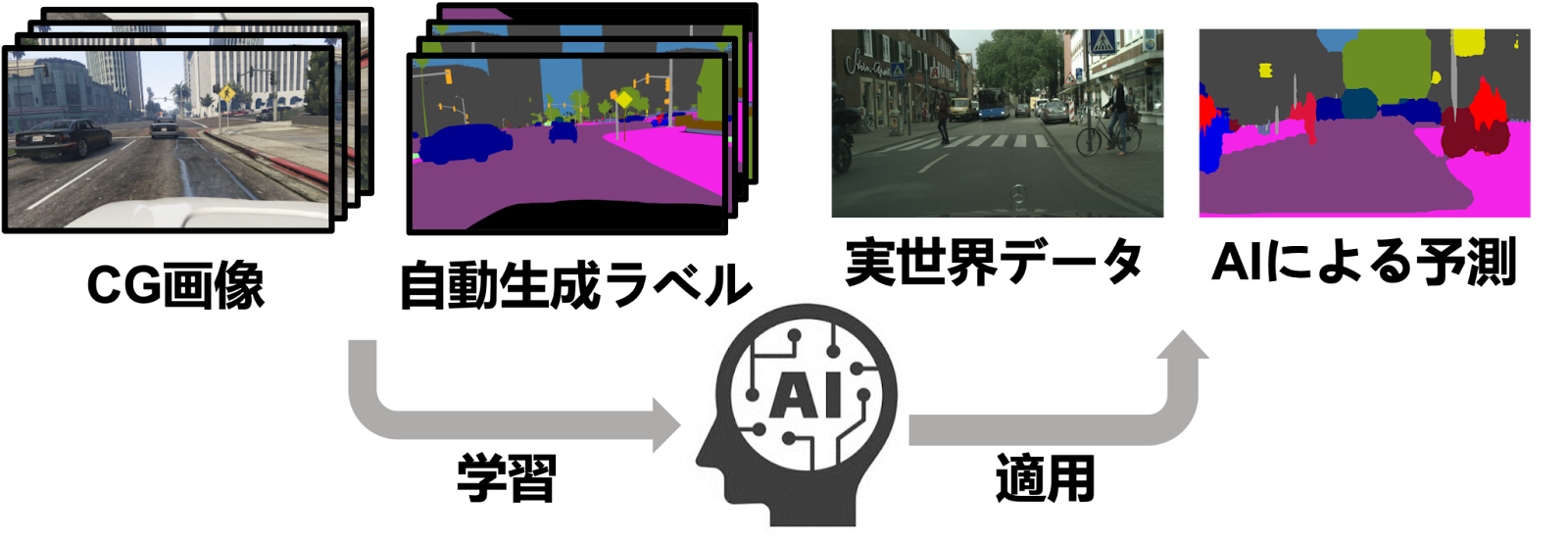
AIの学習には大量のデータおよびそのデータに対応するラベルが必要です.例えば,犬と猫のいずれかを含む画像を分類するAIの学習には,画像およびその画像に犬と猫のどちらが含まれているかを表すラベルを利用します.しかしながら,このようなラベルを大量のデータに対して用意するためには多大な労力が必要です.この問題を解決するため,少量のラベル付きデータからでも学習可能なAIの実現についての検討が行われています.メディアダイナミクス研究室では,ラベルの付与が容易なデータから抽出された知識をラベルがないデータに転用することで,ラベルを必要としないAIを構築しました.具体的には,実世界におけるデータを学習する際に,ラベルの付与やデータの収集が容易なゲームなどのCGデータから抽出した知識を利用することで,実社会におけるデータに対してラベルを必要としないAIの学習を実現しました.
人間が解釈可能な内部表現の学習
深層学習技術は,画像や映像等の複雑なデータが有する特徴を自動で抽出し,様々なタスクにおいて高精度化を実現したことで近年注目を集めています.一方で,深層学習から抽出された特徴は複雑であり,その特徴を人間が理解することは困難です.そのため,深層学習がタスクの遂行ために行った判断の根拠が不明瞭であり,説明性や解釈性の低下を招いています.深層学習の判断根拠を人間が理解可能な形式で表現することはこれらの説明性や解釈性の向上に重要であり,深層学習が社会応用へ向けて発展するための重要な契機になると考えられます.そこで,メディアダイナミクス研究室では,抽出された特徴を形や色などの人間が理解可能な要素で表現することで,より様々なタスクに応用可能な特徴表現を獲得する研究を行っています.本研究により抽出された特徴の解析が進むことで,説明性や解釈性の高い深層学習手法の実現が期待されます.
